کاواندیش
در این وبلاگ خلاصه مطالعات یا تجارب جالب توجه خود در مورد هوشمندی کسب و کار(BI) را منتشر خواهم کرد.کاواندیش
در این وبلاگ خلاصه مطالعات یا تجارب جالب توجه خود در مورد هوشمندی کسب و کار(BI) را منتشر خواهم کرد.آشنایی با داده کاوی
در طول دهه گذشته حجم زیادی از داده ها در پایگاه داده ها انباشته و ذخیره شده اند و روند افزایش آن همچنان ادامه دارد به گونه ای که داده های در دسترس هر 5 سال دو برابر می شود. در این میان تحقیقات انجام یافته نشان از آن دارد که سازمانها امروزه کمتر از یک درصد از داده هایشان را برای تحلیل استفاده می نمایند. به عبارت دیگر سازمانها در حالی تشنه دانش هستند که در داده ها غرق شده اند چرا که پردازش چنین حجم عظیمی از داده از توان انسان خارج است.
در سالهای اخیر در پاسخ به این امر، رشته جدیدی از کاوش داده ها موسوم به داده کاوی(Data Mining) به طور ویژه گسترش یافته است تا اطلاعات با ارزشی از چنین مجموعه داده های عظیم استخراج نماید. نگاهی به ترجمه تحت اللفظی داده کاوی، به ما در درک بهتر این واژه کمک می کند. کاوش(Mining) به معنای جستجو و استخراج از منابع نهفته و با ارزش زمین اطلاق می شود. پیوند این کلمه با کلمه داده، جستجوی عمیق جهت پیدا کردن اطلاعات مفیدی که قبلاً نهفته بودند، از داده های قابل دسترس حجیم را پیشنهاد می کند.
داده کاوی یک رشته نسبتاً جدید علمی می باشد که از انجام تحقیقات حداقل در رشته های آمار، یادگیری ماشین، بازنمایی دانش، علوم رایانه خصوصاً مدیریت پایگاه داده ها شکل گرفته است.
داده کاوی دارای تعاریف متنوعی می باشد. این تعاریف به مقدار زیادی به پیش زمینه ها و نقطه نظرهای افراد ارائه دهنده بستگی دارد که در اینجا به برخی از آنها اشاره می کنیم:
1- داده کاوی فرآیند شناخت الگوهای معتبر، جدید، ذاتاً مفید و قابل فهم از داده ها می باشد. (Fayyad)
2- داده کاوی به فرآیند استخراج اطلاعات نهفته، قابل فهم، قابل پی گیری از پایگاه داده های بزرگ و استفاده از آن در تصمیم گیری های تجاری مهم، اطلاق می شود.(Zekulin)
3- داده کاوی، مجموعه ای از روش ها در فرآیند کشف دانش می باشد که برای تشخیص الگوها و روابط نامعلوم در داده ها مورد استفاده قرار می گیرد. (Ferruzza)
4- فرآیند کشف الگوهای مفید از داده ها را داده کاوی می گویند. (John)
5- فرآیند انتخاب، کاوش و مدل بندی داده های حجیم، جهت کشف روابط نهفته با هدف بدست آوردن نتایج واضح و مفید، برای مالک پایگاه داده ها را، داده کاوی گویند.
در واقع داده کاوی به استخراج دانش از پایگاه های بزرگ داده ها اشاره دارد. این الگوها از قبل شناخته شده نبوده اند و یافتن آنها با روش های تحلیل دستی بسیار زمانگیر یا غیر ممکن می باشد.
پیش از پرداختن به انواع الگوریتم های داده کاوی به برخی کاربردهای آن در حوزه های مختلف اشاره می کنیم:
خرده فروشی
تعیین الگوهای خرید مشتریان
تجزیه و تحلیل سبد خرید بازار
پیشگویی میزان خرید مشتریان از طریق فروش الکترونیکی
بانکداری
پیش بینی الگوهای کلاهبرداری از طریق کارت های اعتباری
تشخیص مشتریان ثابت و شناخت مشتریان پر خطر و سودجو براساس معیار هایی از جمله سن ، درآمد، وضعیت سکونت، تحصیلات، شغل و غیره
تشخیص اقدامات مرتبط با پولشویی
بیمه
تجزیه و تحلیل دعاوی و شناسایی ادعاهای متقلبانه
پیشگویی میزان خرید بیمه نامه های جدید توسط مشتریان
پزشکی
تعیین میزان موفقیت روش های درمانی در برخورد با بیماری های صعب العلاج
کشف الگوها و مدلهای ناشناخته تاثیر دارو ها بر بیماری های مختلف
کشف الگوها و مدلهای ناشناخته تاثیر دارو ها بر بیماران گروه سنی مختلف
هواشناسی
استفاده از الگوها برای پیش بینی وضعیت هوا
روزنامه نگاری
شناسایی گروه های مختلف خوانندگان و ارائه مطالب متناسب
انتشارات
شناسایی الگوی خرابی دستگاه های چاپ
تبلیغات
بخش بندی بازار و ارائه تبلیغات متناسب
روانشناسی
کشف الگوهایی در رابطه با ازداوجهای موفق و ناموفق
کشف عوامل های مختلف در اعتیاد افراد
امروزه مرز و محدودیتی برای دانش داده کاوی متصور نبوده و کاربرد آن را از کف اقیانوس ها تا اعماق فضا می دانند. به طور کلی هرکجا حجم زیادی داده موجود باشد، پتانسیل اجرای بررسی های داده کاوی وجود دارد.
آشنایی با پاکسازی اطلاعات

با توجه به نقش انکارناپذیر اطلاعات در هوشمندی کسب و کار، برخورداری از اطلاعات با کیفیت دارای اهمیت دوچندان خواهد بود. عدم بهره مندی از چنین سطحی از کیفیت، بسیاری از تحلیل ها و برنامه ریزی ها را غیرممکن می سازد و چه بسیار تهدیدها و فرصتها که به این ترتیب قابل کشف نخواهند بود.
پاکسازی داده فرایند تشخیص، اصلاح و حذف خطاهای موجود در داده هاست. خطاهای داده شامل داده های غلط، ناقص، تکراری، متناقض ویا با ساختار نامناسب هستند. برای بیان این تعریف از عبارات تمیز کردن داده یا پالایش داده هم استفاده می شود.
در این نوشتار برخی اصول اولیه پاکسازی اطلاعات را ذکر می کنیم. مطالب تکمیلی در آینده به
تدریج اضافه خواهند شد.
سه اصل کلیدی پاکسازی اطلاعات
1- پیشگیری بهتر از درمان است.
لازم است دو رویه پاکسازی اطلاعات و پیشگیری از خطا به موازات هم پیش بروند. تصمیم بر پاکسازی اطلاعات و سپس اندیشیدن به پیشگیری از خطا بدان معناست که خطاها مجدداً بروز خواهند کرد و رویه پاکسازی بایستی مجدداً تکرار شود. همچنین روند پاکسازی اطلاعات به شناسایی علت خطاها و در پیش گرفتن تدابیری جهت پیشگیری از بروز مجدد آنها کمک میکند.
2- حفظ کیفیت اطلاعات یک وظیفه همگانی است.
چرخه مدیریت اطلاعات شامل کاربران واردکننده اطلاعات، واحدهای پشتیبانی از اطلاعات و کاربران استفاده کننده از اطلاعات می باشد. هریک از این کاربران به گونه ای در حفظ کیفیت اطلاعات موثر هستند. به عنوان مثال دقت کاربران در هنگام ورود اطلاعات، بررسی دوره ای کیفیت اطلاعات توسط واحدهای پشتیبانی و ارائه بازخورد از طرف کاربران استفاده کننده از اطلاعات از عوامل مهم در حفظ و ارتقای کیفیت اطلاعات هستند.
3- نقش آموزش در حفظ کیفیت اطلاعات
بسیاری از نقصهای اطلاعاتی ناشی از آن است که کاربران جهت سرعت بخشیدن به کار خود بدون آگاهی از اهمیت اطلاعات وارده، از ورود برخی اقلام صرف نظر کرده یا مقادیر را به صورت پیش فرض رها می کنند. آموزش کاربران واردکننده اطلاعات و آگاه سازی آنها از اهمیت ورود صحیح اطلاعات و در ادامه کنترل و پیگیری کیفیت اطلاعات وارد شده توسط آنها در فرآیند حفظ کیفیت اطلاعات اهمیت بسزایی دارد.
عوامل ایجاد خطا در سیستمهای اطلاعاتی
برخی از مهمترین عوامل بروز خطا در سیستمهای اطلاعاتی عبارتند از:
- عدم وجود فرمت مناسب در سیستم ورود اطلاعات( به عنوان مثال تاریخها)
- عدم اعتبارسنجی محدوده مقادیر وارد شده( به عنوان مثال سن فرد 300 سال وارد شود)
- اجباری نبودن وارد کردن مقادیر
- اکتفا به مقادیر پیش فرض سیستم و عدم ورود اطلاعات دقیق
- تغییرات سیستم در طی زمان و اضافه شدن تدریجی اقلام اطلاعاتی
- عدم یکپارچگی سیستمها و تکرار اطلاعات
- امکان وارد کردن چند مقدار در یک فیلد( به عنوان مثال، وارد کردن چند شماره در کنار هم به عنوان شماره تلفن)
- عدم دقت کاربران در ورود اطلاعات
پی نوشت: مطالب ذکر شده در این نوشتار بخشی از مقاله ای می باشد که توسط اینجانب در ماهنامه داخلی شرکت بیمه پارسیان منتشر شده است.
XMLA
XMLA استانداردی است که امکان ارتباط بین برنامه های مشتری با منابع داده چند بعدی را فراهم می کند. این استاندارد در سال 2000 توسط مایکروسافت ارائه گردید و به فاصله ای اندک، کمپانی های SAS و Hyperion به انجمن XMLA پیوستند و در حال حاضر بیش از 25 شرکت حامی این انجمن هستند.
در توسعه XMLA از استاندارهای مستقل موجود استفاده شده است شاملHTTP، SOAP و XML. زبان پرس و جو نیز MDX می باشد که استاندارد پرس و جوهای چند بعدی می باشد.
محصولات مایکروسافت این استاندارد را به عنوان پروتکل اصلی خود برای تمامی ارتباطات با Analysis Services مورد استفاده قرار می دهند. به عنوان مثال، در استفاده از AMO و ADOMD.NET نیز درخواست ها به دستورات XMLA تبدیل می شوند.
این استاندارد شامل دو متد اصلی است: Discover و Execute. متد Discover جهت دریافت اطلاعات و متادیتا استفاده می شود؛ از قبیل فهرستی از منابع داده، کیوب ها، ابعاد، نقش ها و .... متد Execute به برنامه های کاربردی اجازه می دهد تا فرمان اجرای دستورات متناسب با سرور ارائه دهنده را صادر کنند. این دستورات می توانند دستورات DML یا DDL باشند.
مکانیزم های مدیریت خطا نیز در این استاندارد لحاظ شده اند.
دستور زیر نمونه ای از دستورات Discover می باشد که لیست کیوب های موجود را برمی گرداند:
<Discover xmlns="urn:schemas-microsoft-com:xml-analysis">
<RequestType>MDSCHEMA_CUBES</RequestType>
<Restrictions />
<Properties />
</Discover>
و قطعه کد زیر یک دستور Execute را نشان می دهد که دستور مورد نظر آن تحت <Statement> آورده شده است:
<soap:Envelope>
<soap:Body>
<Execute xmlns="urn:schemas-microsoft-com:xml-analysis">
<Command>
<Statement>SELECT Measures.MEMBERS ON COLUMNS FROM Sales</Statement>
</Command>
<Properties>
<PropertyList>
<DataSourceInfo/>
<Catalog>FoodMart</Catalog>
<Format>Multidimensional</Format>
<AxisFormat>TupleFormat</AxisFormat>
</PropertyList>
</Properties>
</Execute>
</soap:Body>
</soap:Envelope>
در محیط SQL Server Management Studio با انتخاب کردن دکمه Script در پنجره پردازش کیوب یا Dimension می توان کد XMLA متناظر را مشاهده نمود و جهت اجرای انواع عملیات از آن استفاده کرد.
پی نوشت: در این نوشتار فرض بر آن بوده که خواننده مطلب با استانداردهای مرتبط از قبیل XML، SOAP و غیره آشنایی کافی دارد و از ارائه توضیحات آنها خودداری شده است. همچنین با توجه به فراگیر بودن علائم اختصاری ذکر شده، عناوین کامل آورده نشده است.
آشنایی با MDX
MDX یک زبان پرس و جو برروی داده های ذخیره شده در کیوب های OLAP می باشد. این زبان در ابتدا توسط مایکروسافت در سال 1997 مطرح گردید و امروزه بسیاری از ارائه دهندگان محصولات OLAP از آن پشتیبانی می کنند از جمله Oracle، MicroStrategy، SAS، SAP، Teradata، JasperSoft، Cognos.
علی رغم شباهت ظاهری بین این زبان و زبان T-SQL که برای پرس و جو بر روی پایگاه داده رابطه ای استفاده می شود، این دو زبان کاملاً از یکدیگر مستقل هستند. همچنین اگرچه می توان برخی پرس و جوهای MDX را به T-SQL تبدیل کرد ولیکن معمولاً نتیجه آن حتی برای پرس و جوهای ساده ترکیبی پیچیده از دستورات T-SQL خواهد بود.
به هر حال برای آشنایی با این زبان، مقایسه آن با T-SQL می تواند نقطه شروع خوبی باشد. یک دستور ساده T-SQL را در نظر میگیریم:
Select column1, column2, …, column from table
یک دستور ساده MDX نیز فرمت زیر را دارد:
Select axis1 on columns, axis2 on rows from cube
برخی از عبارتها بسیار آشنا هستند همانند select و from و در واقع در MDX هم همان کارکرد را دارند. Select نشان دهنده اجرای یک پرس و جو است و from منبع داده را نشان می دهد. در T-SQL منبع جداول یک پایگاه داده هستند و در MDX منبع یک کیوب است.
اما تفاوت عمده ای بین دو پرس و جوی بالا وجود دارد. نتیجه یک پرس و جوی T-SQL اساساً یک نمای رابطه ای دو بعدی شامل سطرها و ستون هاست. تمامی سطرها ساختار مشخص شده توسط ستونها را دارند و هر ستون می تواند نوع داده مخصوص خود را داشته باشد. حال آنکه MDX محدود به دو بعد نمی باشد. نتیجه یک پرس و جو میتواند صفر، یک، دو، سه و ... بعد یا محور داشته باشد( اگرچه نمایش بیش از سه بعد در صفحه نمایش امکان پذیر نیست). همچنین در پرس و جوی MDX، علاوه بر ساختار ستونها بایستی ساختار سطرها نیز مشخص گردد. اینکار با مشخص کردن مجموعه های چند تایی از اعضای هریک از ابعاد(Dimension) مدنظر از کیوب انجام می شود که اصطلاحاً به آن tuple میگویند.
به عنوان مثال در صورتیکه کیوب ما با نام Sales، شامل دو بعد به نامهای Years(سالها) و Regions(مناطق جغرافیایی) باشد، می توان دستور زیر را نوشت:
select Years.members on columns,
Region.members on rows
from Sales
که خروجی مشابه زیر را تولید می کند:
|
1996 |
1995 |
1994 |
|
|
400.000 |
200.000 |
120.000 |
N. America |
|
70.000 |
30.000 |
- |
S. America |
|
310.000 |
160.000 |
95.000 |
Europe |
با توجه به دستور مربوطه، بر روی ستون ها مقادیر سال های موجود و برروی سطرها عناوین مناطق دیده می شود. ولیکن اعداد نمایش داده شده چه هستند؟ این مقادیر در واقع همان سنجه(Measure) های تعریف شده در کیوب هستند که در صورت نام نبردن از یک سنجه خاص، سنجه پیش فرض(Default Measure) کیوب نمایش داده می شود که در کیوب فوق میتواند میزان فروش باشد.
تفاوت دیگر آنکه، جهت اعمال شرایطی برای پرس و جو در زبان T-SQL از دستور where استفاده می گردید. این عبارت در MDX نیز وجود دارد ولیکن کارکردی کاملاً متفاوت دارد. این دستور در زبان MDX عملیات برش(Slicing) کیوب را انجام می دهد که طی آن بخشی از کیوب با مشخص کردن عناصر هریک از ابعاد جدا میشود.
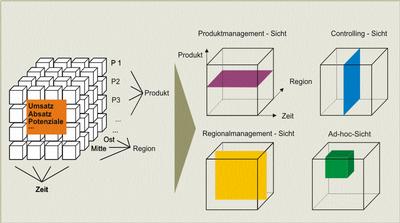
در مقایسه با T-SQL که در آن where به معنای فیلتر کردن سطرها با شرط مشخصی است، این دستور در MDX، محاسبه سنجه را تحت تاثیر قرار می دهد.
به عنوان مثال دستور زیر مشابه دستور قبلی میزان فروش در سال های مختلف هریک از مناطق را نشان می دهد با این تفاوت که محصولات گروه کامپیوتر مد نظر بوده اند:
select Years.members on columns,
Region.members on rows
from Sales
where (Product.Computers)
علاوه بر تفاوت های ذکر شده در این مطلب، دستورات MDX دنیای جدیدی از امکانات را در اختیار می گذارند که دستیابی به آنها توسط دستورات T-SQL غیرممکن یا بسیار دشوار است.
آموزشی مختصر در مورد MDX را در این لینک ببینید.
Open Source BI
برخی بررسی ها نشان داده اند که امروزه حدود 60% شرکتها و سازمانها در سرتاسر دنیا به نحوی از نرم افزارهای متن باز استفاده میکنند؛ خواه به صورت آگاهانه خواه به صورت عناصری که در سایر نرم افزارها نهفته اند. مجموعه ابزارهای کد باز BI نیز در سالهای اخیر رشد قابل توجهی داشته اند. فارغ از مزایا و تهدیدهای استفاده از نرم افزارهای کد باز در BI، که خود مطلب جداگانه ای را می طلبد، در این نوشتار برخی از معروفترین آنها را معرفی می کنیم:
این شرکت مدعی است که رایج ترین نرم افزار مورد استفاده در BI نرم افزار آنها می باشد. از ویژگیهای این محصول انعطاف پذیری واسط کاربر آن می باشد که برای کاربران غیرفنی نیز مناسب است. طراحی گزارشات با Drag&Drop انجام می پذیرد بدون آنکه کاربر درگیر دستورات SQL ایجاد شده در پشت صحنه باشد. همچنین انواع نمودارها، صفحه گسترده ها و حتی انیمیشن های فلش قابل نمایش هستند؛ انواع تبدیل خروجیها نیز قابل انجام هستند از جمله PDF، ODT، RTF، Excel، CSV، XML CSS. اجرای گزارشات می تواند به صورت زمانبندی شده یا در اثر وقوع رویداد باشد.
عملیات ETL نیز در این مجموعه قدرتمند است و داده ها از انواع منابع قابل استخراج هستند. این شرکت برای این کار از نرم افزار Talend استفاده می کند که خود یک توسعه دهنده کدمنبع باز است.
در قسمت داشبورد نیز انعطاف پذیری همانند گزارشات وجود دارد و ابزارهای متداول قابل استفاده هستند.
این مجموعه به دو صورت نسخه مجانی و نسخه حرفه ای که شامل خدمات و پشتیبانی است ارائه می گردد.
این مجموعه ابزار یکی دیگر از بزرگان BI میباشد و نوعی رقابت بین آنها و JasperSoft وجود دارد. JasperSoft مدعی است در BI شماره یک است و Pentaho ادعای رهبری در این عرصه را دارد. JasperSoft ادعای 80% کاهش هزینه با استفاده از ابزار خود را دارد و Pentaho ادعای 90% را! به هر حال هر دو ابزار عالی هستند.
امکانات در اختیار و قابلیت انعطاف در هر دو گروه مشابه است. تفاوت در نحوه قیمت گذاری است. Pentaho اشتراک یکساله را ارائه میدهد که پشتیبانی، امکانات فراتر از نسخه مجانی، چرخه های نشر مدیریت شده، دسترسی به مستندات و منابع پشتیبانی بیشتر، آموزش و رفع خطا و بروزرسانی ها را شامل میشود.
هر دو گروه همچنین امکان استفاده پیش از خرید را ارائه می دهند.
مجموعه Pentaho به صورت ماژولار طراحی شده است و کاربر می تواند تمام یا بخشی از امکانات را مورد استفاده قرار دهد.
Spago یک پروژه BI جالب توجه است که خود را تنها مجموعه BI کاملاً کد منبع باز معرفی می کند. این مجموعه به زبان جاوا نوشته شده است و نرم افزار و امکان پشتیبانی جامعه توسعه دهنده در آن برای همیشه رایگان است. آموزش، پشتیبانی تجاری، مشاوره و توسعه های خاص شامل هزینه هستند.
Spago اشتراکات زیادی با سایر مجموعه های کد باز BI دارد همانند Talend برای ETL، داشبوردها، پشتیبانی از انواع فرمت مستندسازی، پشتیبانی از انواع پایگاه داده( Oracle، MySql، PostgreSQL، Ingres، Microsoft SQL Server) و موتور گزارش گیری JasperReports. این مجموعه همچنین شامل یک کنسول مانیتورینگ برخط و موتورهای GEO/GID برای داده های مکانی است.
شعار Actuate "مجموعه ای برای امکانات مجتمع در یک محیط" است. این مجموعه بر اساس BIRT ساخته شده است که خود بر جاوا و Eclipse استوار است.
تاکید Actuate بر کاربردهای غنی از اطلاعات است که تعاملی و پویا هستند و در این راه از Adobe Flash و تجمیع چندین منبع و اطلاعات مکانی استفاده میکند.